
Mainframes. They’ve been the butt of IT jokes since at least the 1990s, but they’re still a remarkably solid business for their biggest manufacturer, (IBM). While Big Blue’s hardware business continues to lose money overall, mainframe revenue keeps growing—including by a whopping 118% in the second quarter (third quarter growth was a more earthly 9%).
And on Tuesday, a company called Syncsort, which specializes in helping businesses integrate their mainframes with more-modern data-management technologies, released a new open source tool that connects IBM Series z mainframes with Apache Spark. It’s an attempt to bring often-conservative mainframe users into the world of 21st-century analytics where they desperately want to be.
Spark is an open source data-processing platform that has dominated the Big Data world over the past couple years. Spark is faster, more flexible and easier to use than Hadoop MapReduce, the open source technology that helped spur interest in Big Data over the past decade, and even has well-funded Hadoop vendors like Cloudera and Hortonworks (HDP) rebuilding parts of their strategies around it. In June, IBM itself announced a $300 million investment toward Spark’s development, calling it “a foundational technology platform for accelerating innovation and driving analytics across every business in a fundamental way.”
To get a sense of Spark’s growing popularity compared with mainframes, check out this trend analysis from job-search site Indeed.
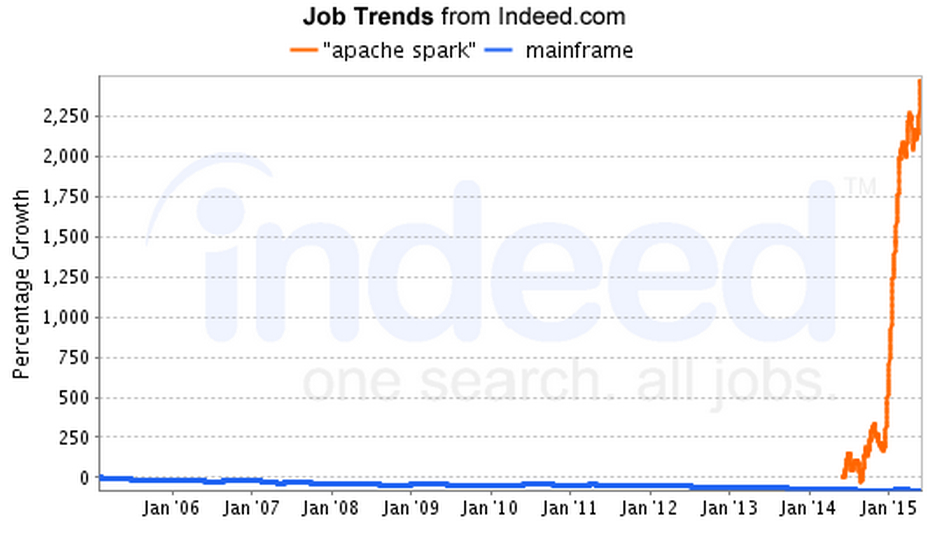
Mainframe users might be locked into a decades-old computing architecture, but they don’t want to locked out of analyzing their data like today’s smart young companies. Last year, I spoke with an executive at Lockheed Martin who explained that major government programs such as Food Stamps and Social Security still run on mainframes, and the agencies in charge of them want to analyze that data using modern techniques and against the mountains of data they’re collecting from other sources. The same goes for the large airlines, banks, and Fortune 500 companies that also still run very important applications on mainframes.
Historically, moving data from one system to another involved an often-complex process called extract-transform-load, or ETL, which has become a dirty word among some data scientist types. But with the type of connector Syncsort has built, these companies and agencies can pull centralized mainframe data into their distributed (read “less expensive, more scalable and likely open source”) Big Data systems and hopefully analyze it with minimal effort.
Think about it like buying the new lightish-calorie Coca-Cola Life soft drink that’s made with cane sugar and Stevia instead of corn syrup. Companies might not be willing or able to give up their mainframes, but tools to help integrate mainframes with the new systems they want to use can help companies feel a little better about that decision.
For more about IBM, watch this Fortune video:











